Data Science with Scala and Smile¶
Monte Carlo Simulation¶
Complete source code on GitHub
This example shows how to use the Monte Carlo method to estimate the area of a circle, recast as data-driven instead of memory-driven to show how to do basic dataset generation and analysis.
First, we’ll look at the code for generating a data file for the Monte Carlo simulation, given the desired number of darts. The resulting file consisting the x- and y-coordinates of each dart along with a boolean flag indicating whether or not the dart landed inside the circle.
1//> using scala 3.3.7
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "me.tongfei:progressbar:0.10.2"
4
5import mainargs.{main, arg, ParserForMethods}
6
7import java.nio.file.{Path, Files, StandardOpenOption}
8import java.nio.charset.StandardCharsets
9
10import me.tongfei.progressbar.*
11import scala.jdk.CollectionConverters.*
12
13
14object GenerateDarts:
15
16 def main(args: Array[String]): Unit = ParserForMethods(this).runOrExit(args.toIndexedSeq)
17
18 @main(doc = "Generate random darts for Monte Carlo simulation")
19 def run(
20 @arg(short = 'n', doc = "Number of darts to generate") n: Int = 1000000,
21 @arg(short = 'o', doc = "Output CSV file") output: String = "darts.csv"
22 ): Unit =
23
24 val random = scala.util.Random
25
26 Files.writeString(Path.of(output), s"x,y,inside\n", StandardCharsets.UTF_8)
27
28 ProgressBar.wrap((1 to n).asJava, "Generating").asScala.foreach: i =>
29 val x = random.nextDouble() * 2 - 1
30 val y = random.nextDouble() * 2 - 1
31 val inside = x * x + y * y <= 1
32
33 Files.writeString(Path.of(output), s"$x,$y,$inside\n", StandardCharsets.UTF_8, StandardOpenOption.APPEND)
34
35 println(s"\nGenerated $n darts and saved to $output")
Next, we’ll look at the code for estimating the area of a circle using the Smile library for statistical computing and machine learning in Scala. In particular, our code loads dataframes representing the points where the darts landed and figures the area of the circle from the ratio of darts that landed inside the circle to the total number of darts.
1//> using scala 3.3.7
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "com.github.haifengl::smile-scala:5.2.2"
4//> using dep "org.slf4j:slf4j-simple:2.0.17"
5
6import mainargs.{main, arg, ParserForMethods}
7import java.nio.file.{Path, Files}
8import java.nio.charset.StandardCharsets
9import smile.data.DataFrame
10import smile.io.Read
11import org.apache.commons.csv.CSVFormat
12
13object EstimateArea:
14
15 def main(args: Array[String]): Unit = ParserForMethods(this).runOrExit(args.toIndexedSeq)
16
17 @main(doc = "Monte Carlo area estimator")
18 def run(
19 @arg(short = 'i', doc = "Input CSV file of darts (default: darts.csv)") input: String = "darts.csv",
20 @arg(short = 'o', doc = "Optional output file to write the estimated area") output: Option[String] = None
21 ): Unit =
22
23 if !Files.exists(Path.of(input)) then
24 println(s"Input file '${input}' does not exist.")
25 sys.exit(1)
26
27 val df: DataFrame = Read.csv(input,
28 CSVFormat.DEFAULT.builder().setHeader().setSkipHeaderRecord(true).get()
29 )
30
31 val totalCount = df.nrow()
32
33 if totalCount == 0 then
34 println(s"Input file '${input}' is empty.")
35 sys.exit(1)
36
37 val insideCount = df.stream().filter(row => row.getBoolean("inside")).count()
38 val estimatedArea = 4.0 * insideCount / totalCount
39 val resultText = f"Estimated area of unit circle: $estimatedArea%.5f using $insideCount/$totalCount darts"
40
41 println(resultText)
42
43 output.foreach: outputPath =>
44 Files.writeString(Path.of(outputPath), resultText + "\n", StandardCharsets.UTF_8)
45 println(s"Result also written to ${outputPath}")
Going Between Java and Scala APIs¶
When using Java-centric APIs, such as Smile, we often need to convert between Java and Scala collections.
This example shows how to convert between the two using the asScala and asJava methods.
These conversions are not strictly needed unless we want to interact with these collections in a Scala way, which we usually do when using Scala.
scala> import scala.jdk.CollectionConverters.*
scala> java.util.List.of("hello", "world")
val res0: java.util.List[String] = [hello, world]
scala> res0.asScala
val res1: scala.collection.mutable.Buffer[String] = Buffer(hello, world)
scala> res1.asJava
val res3: java.util.List[String] = [hello, world]
scala> List("hola", "mundo")
val res4: List[String] = List(hola, mundo)
scala> res4.asJava
val res5: java.util.List[String] = [hola, mundo]
Graffiti/311 Chicago Data Portal¶
Complete source code on GitHub
This example aims to introduce Scala + Smile with a compelling example from our hometown of Chicago. Well, it could be any city!
The Chicago Data Portal Graffiti/311 example provides a lightweight, scriptable toolkit for analyzing graffiti-related 311 service requests in the City of Chicago. Using Scala and command-line tools, the system allows users to inspect, filter, aggregate, and visualize graffiti complaint data efficiently—even on large files.
While graffiti is often–and wrongly–perceived as a cosmetic or quality-of-life issue, tracking and understanding patterns in graffiti reports can reveal deeper insights into urban infrastructure, neighborhood disinvestment, and resident engagement.
311 calls are not limited to being complaints; they are a form of civic participation. By examining this data over time and across geographic regions, we gain valuable information about public responsiveness, spatial inequality, and where municipal services are (or aren’t) being delivered equitably to communities (a longstanding issue in many Chicago neighborhoods).
This demonstration application helps make that analysis transparent, reproducible, and accessible.
Requirements (Functional and Non-Functional)¶
Data Acquisition¶
The system must be able to:
Download the Chicago 311 graffiti removal dataset in CSV format from the City of Chicago’s open data portal.
Data Inspection¶
The system must be able to:
Load and parse the downloaded CSV file, treating the first line as a header.
Display the dataset schema (column names).
Preview a limited number of rows from the dataset.
Data Filtering¶
The system must be able to:
Filter requests based on:
Service status (e.g., “Completed”, “Open”).
A start date and/or end date range using the “Creation Date” column.
Limit the number of matching rows displayed.
Save the filtered dataset to a new CSV file.
Data Aggregation¶
The system must be able to:
Count the number of requests grouped by a specific column (e.g., “Zip Code” or “Surface Type”).
Display the top N group values by count.
Data Visualization¶
The system must be able to:
Aggregate requests by month using the “Creation Date” column.
Generate a bar chart of graffiti removal trends over time.
Save the chart to a file (e.g., PNG), with no GUI dependencies.
Reproducibility & Automation¶
The system must be able to:
Be scriptable and composable using CLI arguments (no hardcoded values).
Use lazy evaluation where possible to minimize memory usage on large files.
Avoid dependence on any GUI (especially for visualization or preview).
Implementation¶
Downloader¶
1//> using scala "3.3.7"
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3
4import java.io.{BufferedInputStream, FileOutputStream}
5import java.net.URI
6import mainargs._
7
8object FetchGraffitiData:
9 val datasetURL = "https://data.cityofchicago.org/api/views/hec5-y4x5/rows.csv?accessType=DOWNLOAD"
10
11 @main
12 def run(
13 @arg(name = "output", short = 'o', doc = "Path to save the downloaded CSV file")
14 output: String = "311_graffiti.csv"
15 ): Unit =
16 val urlStream = new BufferedInputStream(URI.create(datasetURL).toURL().openStream())
17 val fileOut = new FileOutputStream(output)
18
19 urlStream.transferTo(fileOut)
20
21 urlStream.close()
22 fileOut.close()
23
24 println(s"Downloaded dataset to $output")
25
26 def main(args: Array[String]): Unit =
27 ParserForMethods(this).runOrExit(args.toIndexedSeq)
1mkdir -p dataset
2curl -L -o dataset/311_graffiti.csv "https://data.cityofchicago.org/api/views/hec5-y4x5/rows.csv?accessType=DOWNLOAD"
Loader¶
1//> using scala "3.3.7"
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "org.apache.commons:commons-csv:1.14.1"
4
5import java.nio.file.{Files, Paths}
6import java.nio.charset.StandardCharsets
7import scala.jdk.CollectionConverters.*
8import org.apache.commons.csv.*
9import mainargs._
10
11object LoadGraffitiData:
12 @main
13 def run(
14 @arg(name = "input", short = 'i') input: String,
15 @arg(name = "limit", short = 'l') limit: Int = 5
16 ): Unit =
17 val reader =
18 Files.newBufferedReader(Paths.get(input), StandardCharsets.UTF_8)
19 val parser = CSVFormat.DEFAULT.builder().setHeader().setSkipHeaderRecord(true).get().parse(reader)
20
21 val headers = parser.getHeaderNames.asScala
22 println(s"Headers: ${headers.mkString(", ")}")
23
24 val iter = parser.iterator().asScala
25 println(s"\nFirst $limit rows:")
26 iter
27 .take(limit)
28 .foreach: record =>
29 val row = headers.map(h => s"$h=${record.get(h)}").mkString(", ")
30 println(row)
31
32 def main(args: Array[String]): Unit =
33 ParserForMethods(this).runOrExit(args.toIndexedSeq)
Filtering¶
This shows how to filter based on some criteria. In this case, we are filtering dates/status of a particular report.
1//> using scala "3.3.7"
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "org.apache.commons:commons-csv:1.14.1"
4
5import java.nio.file.{Files, Paths}
6import java.nio.charset.StandardCharsets
7import java.time.LocalDate
8import java.time.format.DateTimeFormatter
9import scala.jdk.CollectionConverters.*
10import org.apache.commons.csv.*
11import mainargs._
12
13object FilterGraffitiData:
14 @main
15 def run(
16 @arg(name = "input", short = 'i') input: String,
17 @arg(name = "status", short = 's') status: String = "Completed",
18 @arg(name = "start-date") startDate: String = "2000-01-01",
19 @arg(name = "end-date") endDate: String = "2025-12-31",
20 @arg(name = "limit", short = 'l') limit: Int = 5,
21 @arg(name = "count-only", doc = "If set, only print number of matching rows") countOnly: Boolean = false
22 ): Unit =
23
24 val reader = Files.newBufferedReader(Paths.get(input), StandardCharsets.UTF_8)
25 val parser = CSVFormat.DEFAULT.builder().setHeader().setSkipHeaderRecord(true).get().parse(reader)
26 val headers = parser.getHeaderNames.asScala
27 val fmt = DateTimeFormatter.ofPattern("MM/dd/yyyy")
28
29 val filtered = parser.iterator().asScala.filter: record =>
30 val rowStatus = record.get("Status")
31 val rowDate = LocalDate.parse(record.get("Creation Date"), fmt)
32
33 val statusOK = rowStatus == status
34 val startOK = !rowDate.isBefore(LocalDate.parse(startDate))
35 val endOK = !rowDate.isAfter(LocalDate.parse(endDate))
36
37 statusOK && startOK && endOK
38
39 if countOnly then
40 val total = filtered.size
41 println(s"$total matching rows.")
42 else
43 val taken = filtered.take(limit).toList
44 println(s"Showing ${taken.size} matching rows:")
45 taken.foreach: record =>
46 val row = headers.map(h => s"$h=${record.get(h)}").mkString(", ")
47 println(row)
48
49 def main(args: Array[String]): Unit =
50 ParserForMethods(this).runOrExit(args.toIndexedSeq)
Aggregation¶
1//> using scala "3.3.7"
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "org.apache.commons:commons-csv:1.14.1"
4
5import java.nio.file.{Files, Paths}
6import java.nio.charset.StandardCharsets
7import scala.jdk.CollectionConverters.*
8import org.apache.commons.csv.*
9import mainargs._
10
11object AggregateGraffitiData:
12 @main
13 def run(
14 @arg(name = "input", short = 'i') input: String,
15 @arg(name = "group-by", short = 'g') groupBy: String = "ZIP Code",
16 @arg(name = "top", short = 't') top: Int = 10
17 ): Unit =
18 val reader = Files.newBufferedReader(Paths.get(input), StandardCharsets.UTF_8)
19 val parser = CSVFormat.DEFAULT.builder().setHeader().setSkipHeaderRecord(true).get().parse(reader)
20
21 val counter = scala.collection.mutable.Map.empty[String, Int].withDefaultValue(0)
22 val iter = parser.iterator().asScala
23
24 iter.foreach: record =>
25 val key = record.get(groupBy)
26 counter(key) += 1
27
28 val sorted = counter.toSeq.sortBy(-_._2).take(top)
29 println(s"Top $top entries grouped by '$groupBy':")
30 sorted.foreach:
31 case (k, v) => println(f"$k%-20s → $v%5d")
32
33 def main(args: Array[String]): Unit =
34 ParserForMethods(this).runOrExit(args.toIndexedSeq)
Visualization¶
1//> using scala "3.3.7"
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "org.apache.commons:commons-csv:1.14.1"
4//> using dep "org.knowm.xchart:xchart:3.8.8"
5
6import java.nio.file.{Files, Paths}
7import java.nio.charset.StandardCharsets
8import java.time.LocalDate
9import java.time.format.DateTimeFormatter
10import scala.jdk.CollectionConverters.*
11import org.apache.commons.csv.*
12import org.knowm.xchart.{CategoryChartBuilder, BitmapEncoder}
13import org.knowm.xchart.BitmapEncoder.BitmapFormat
14import mainargs._
15
16object VisualizeGraffitiData:
17 @main
18 def run(
19 @arg(name = "input", short = 'i') input: String,
20 @arg(name = "output", short = 'o') output: String = "graffiti_trend.png"
21 ): Unit =
22 val reader = Files.newBufferedReader(Paths.get(input), StandardCharsets.UTF_8)
23 val parser = CSVFormat.DEFAULT.builder().setHeader().setSkipHeaderRecord(true).get().parse(reader)
24 val fmt = DateTimeFormatter.ofPattern("MM/dd/yyyy")
25
26 val monthly = scala.collection.mutable.Map.empty[String, Int].withDefaultValue(0)
27 parser.iterator().asScala.foreach: record =>
28 val date = LocalDate.parse(record.get("Creation Date"), fmt)
29 val key = f"${date.getYear}-${date.getMonthValue}%02d"
30 monthly(key) += 1
31
32 val (months, counts) = monthly.toSeq.sortBy(_._1).unzip
33
34 val chart = new CategoryChartBuilder()
35 .width(800).height(600)
36 .title("Graffiti Removal Requests Per Month")
37 .xAxisTitle("Month")
38 .yAxisTitle("Requests")
39 .build()
40
41 chart.addSeries("Requests", months.asJava, counts.asJava.asInstanceOf[java.util.List[Number]])
42 BitmapEncoder.saveBitmap(chart, output, BitmapFormat.PNG)
43
44 println(s"Saved chart to $output")
45
46 def main(args: Array[String]): Unit =
47 ParserForMethods(this).runOrExit(args.toIndexedSeq)
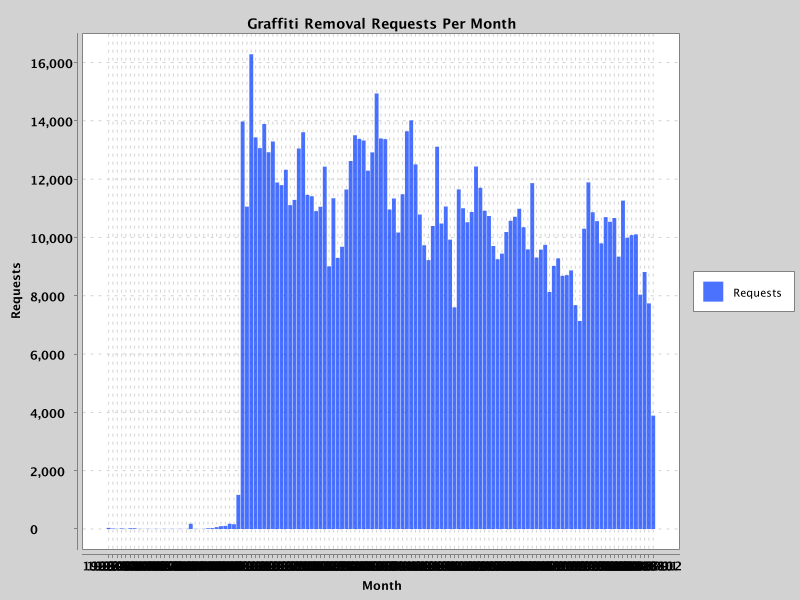
Reproducibility¶
1//> using scala "3.3.7"
2//> using dep "com.lihaoyi::mainargs:0.7.8"
3//> using dep "org.apache.commons:commons-csv:1.14.1"
4
5import java.nio.file.{Files, Paths}
6import java.nio.charset.StandardCharsets
7import java.time.LocalDate
8import java.time.format.DateTimeFormatter
9import scala.jdk.CollectionConverters.*
10import org.apache.commons.csv.*
11import mainargs._
12
13object SaveFilteredGraffitiData:
14 @main
15 def run(
16 @arg(name = "input", short = 'i') input: String,
17 @arg(name = "output", short = 'o') output: String,
18 @arg(name = "status", short = 's') status: Option[String] = None,
19 @arg(name = "start-date") startDate: Option[String] = None,
20 @arg(name = "end-date") endDate: Option[String] = None
21 ): Unit =
22 val reader = Files.newBufferedReader(Paths.get(input), StandardCharsets.UTF_8)
23 val parser = CSVFormat.DEFAULT.builder().setHeader().setSkipHeaderRecord(true).get().parse(reader)
24 val headers = parser.getHeaderNames.asScala
25 val fmt = DateTimeFormatter.ofPattern("MM/dd/yyyy")
26
27 val writer = Files.newBufferedWriter(Paths.get(output), StandardCharsets.UTF_8)
28 val printer = CSVFormat.DEFAULT.builder
29 .setHeader(headers.toSeq*)
30 .get()
31 .print(writer)
32
33 val matched = parser.iterator().asScala.filter: record =>
34 val rowStatus = record.get("Status")
35 val rowDate = LocalDate.parse(record.get("Creation Date"), fmt)
36 val statusOK = status.forall(_ == rowStatus)
37 val startOK = startDate.forall(sd => !rowDate.isBefore(LocalDate.parse(sd)))
38 val endOK = endDate.forall(ed => !rowDate.isAfter(LocalDate.parse(ed)))
39 statusOK && startOK && endOK
40
41 matched.foreach: record =>
42 val row = headers.map(record.get).asJava
43 printer.printRecord(row)
44
45 printer.close()
46 println(s"Wrote filtered records to $output")
47
48 def main(args: Array[String]): Unit =
49 ParserForMethods(this).runOrExit(args.toIndexedSeq)